Simple Prometheus Blackbox Exporter setup for Kubernetes services monitoring
Let’s install Prometheus1 blackbox-exporter2 in a Kubernetes cluster, using its Helm chart3.
We won’t change something in the default values, it’s good enough as it is, but feel free to read it, as you always should, before deploying it.
Then, monitoring an internal Kubernetes service is as simple as adding the following scrape configuration to prometheus:
- job_name: 'prometheus-blackbox-exporter'
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
- targets:
- https://snipeit.snipeit.svc.cluster.local #example
- https://<my-app-service-name>.<my-app-namespace>.svc.cluster.local #generic
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: _address_
replacement: prometheus-blackbox-exporter:9115
And now you can port-forward the blackbox-exporter and open localhost:9115 and see the checks yourself. By default it is doing one check every minute.

After that, why not set up an alert to trigger when a check fails?
Open up alertmanager4 and add the following configuration:
groups:
- name: BlackboxAlerts
rules:
- alert: DevOps service down
expr: probe_success != 1
for: 1m
labels:
severity: critical
slack-channel: k8s-monitoring
annotations:
summary: "Service {{ $labels.instance }} failed HTTP check."
So, now, assuming that the alertmanager configuration knows how to parse the summary annotation, and has a slack receiver for the #k8s-monitoring Slack channel, then the alert will trigger successfully.
Example snippet from alertmanager configuration:
global:
slack_api_url: 'https://hooks.slack.com/services/<SLACK_SERVICE_INFO>'
route:
group_wait: 10s
group_interval: 5m
repeat_interval: 15m
receiver: 'k8s-monitoring-slack-receiver'
routes:
- receiver: k8s-monitoring-slack-receiver
match_re:
slack-channel: k8s-monitoring
continue: true
receivers:
- name: k8s-monitoring-slack-receiver
slack_configs:
- channel: '#k8s-monitoring'
send_resolved: true
text: '{{ range .Alerts }} {{ .Annotations.summary }}\n\n{{ end }}'
Simple, right?
Here’s how it may look:
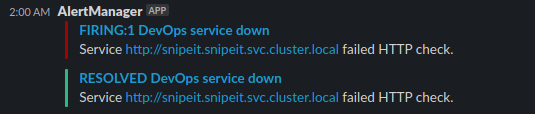
Of course, now you understand that you may add more slack channel receivers, or any other receiver that alertmanager supports. Combine that, with well-thought annotations and annotation handling and you have yourself a nice setup to be alerted when a service seems to be unresponsive.